How We Built a Competitive Memory Retrieval System using Open-Source Models
Mar 3, 2026 · Ensue team
We built a multi-stage retrieval system that scores among the best on LongMemEval, using only open-source models. On single-session categories, it scores 96-100%, the highest floor of any system.
The accuracy scales with the models. When we swap the open-source models with GPT-5-mini, the system's overall accuracy increases from 88.2% to 93.2%. Here is the architecture.
The Problem: Agents accumulate memory faster than they can retrieve meaning from it
Modern agents with persistent memory, such as Claude Code, Codex, and, more recently, agents built using systems like OpenClaw, continuously store your codebase, preferences, and past decisions. Over time, they become more personalized and more effective, because they remember you.
Memory that grows over weeks and months becomes a liability if retrieval degrades. After hundreds of conversations, your agent needs to find the right memory from thousands of entries.
Many systems rely on frontier models at key stages of their retrieval pipeline. We wanted to see how far we could get with open-source models alone, and whether a smarter architecture could close the gap.
Our Approach: Multi-Stage Retrieval System
We split retrieval into two distinct phases: ingestion and querying. Each phase is handled by a pipeline of small, specialized models: embeddings, open-source language models, and a fine-tuned classifier.
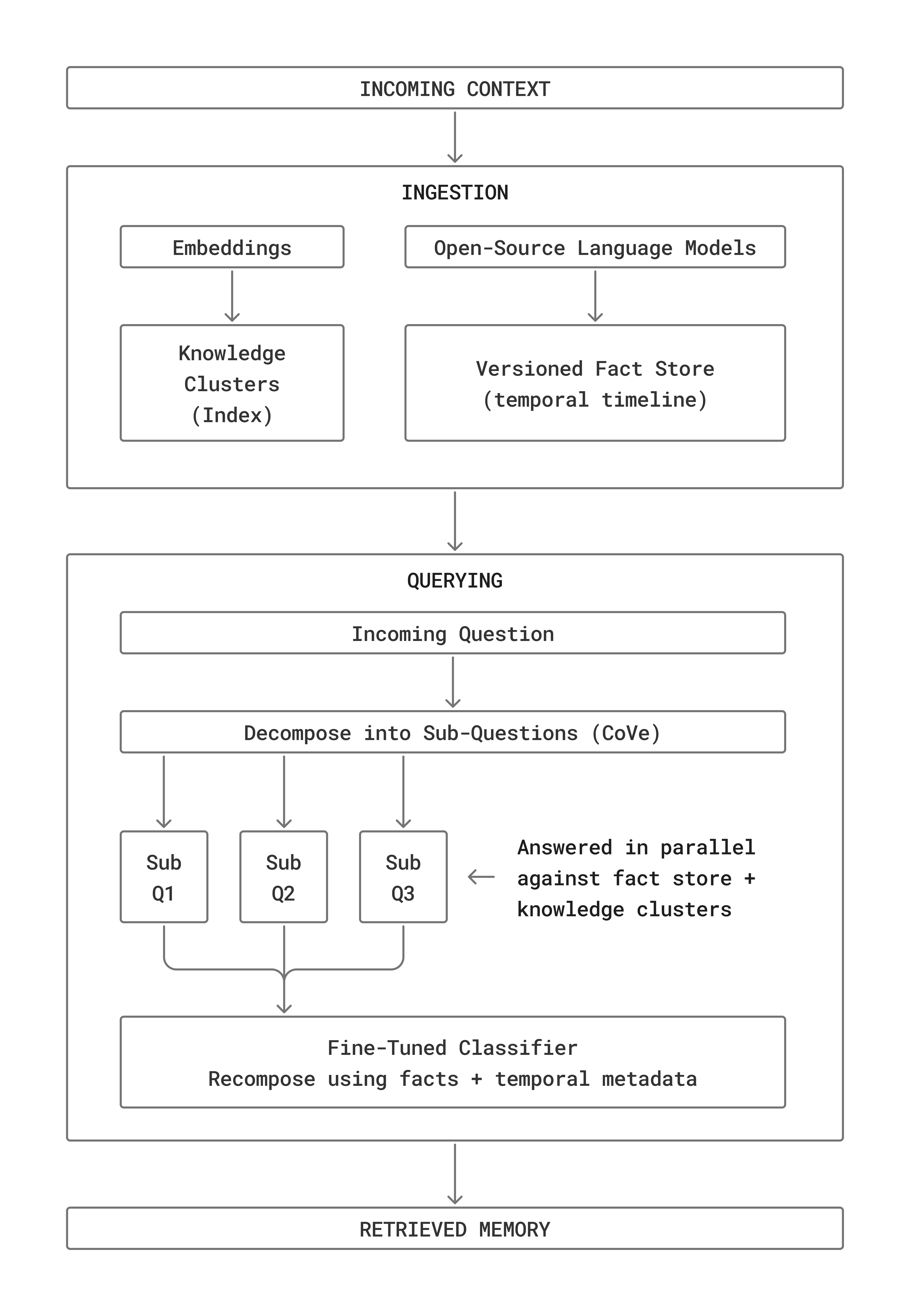
Ingestion
Ingestion processes incoming context into a versioned fact store and knowledge clusters. The fact store creates a granular timeline of what was said and when, aiding temporal tracking, lexical analysis, and semantic retrieval. The knowledge clusters, inspired by page index (Zhang et al., 2025), act as a real-time table of contents for everything in the context window. Together, these structures give the query phase something far richer to search over than raw embeddings.
Querying
Querying draws on the Chain-of-Verification (CoVe) technique (Shehzaad et al., 2023). Rather than answering a question in a single pass, the pipeline decomposes it into sub-questions, answers each in parallel against the ingested fact store and knowledge clusters, and recomposes the final answer using facts and temporal metadata. This is what enables the near-perfect single-session accuracy. The system doesn't just find similar text, it reasons over structured memory.
RLM-Based Retrieval Layer
Beyond the benchmark pipeline, we've also built an agentic retrieval layer: an RLM-based sub-agent (Zhang et al., 2026) that uses Ensue's persistent memory as its search backend, dynamically obtaining relevant context across sessions. This layer improves as the underlying models improve - and open-source models are improving fast.
Because the pipeline runs entirely on open-source models, it can run on your own hardware. Privacy, low latency, and control over your infrastructure come out of the box. And as open-source models continue to improve, our accuracy ceiling rises without changing the architecture.
Benchmark Comparison: Top Accuracy in Single-Session Categories
We evaluated the system on LongMemEval: 500 questions over chat histories exceeding 115K tokens, testing recall, temporal reasoning, knowledge updates, and filtering noise across sessions. It's the most rigorous benchmark for long-term agent memory.
Our pipeline with open-source models scored 88.2% overall, competitive with systems running frontier, proprietary models like GPT-5-mini and Gemini-3-pro. On single-session categories, where retrieval accuracy matters most for the user experience, we are best in class.
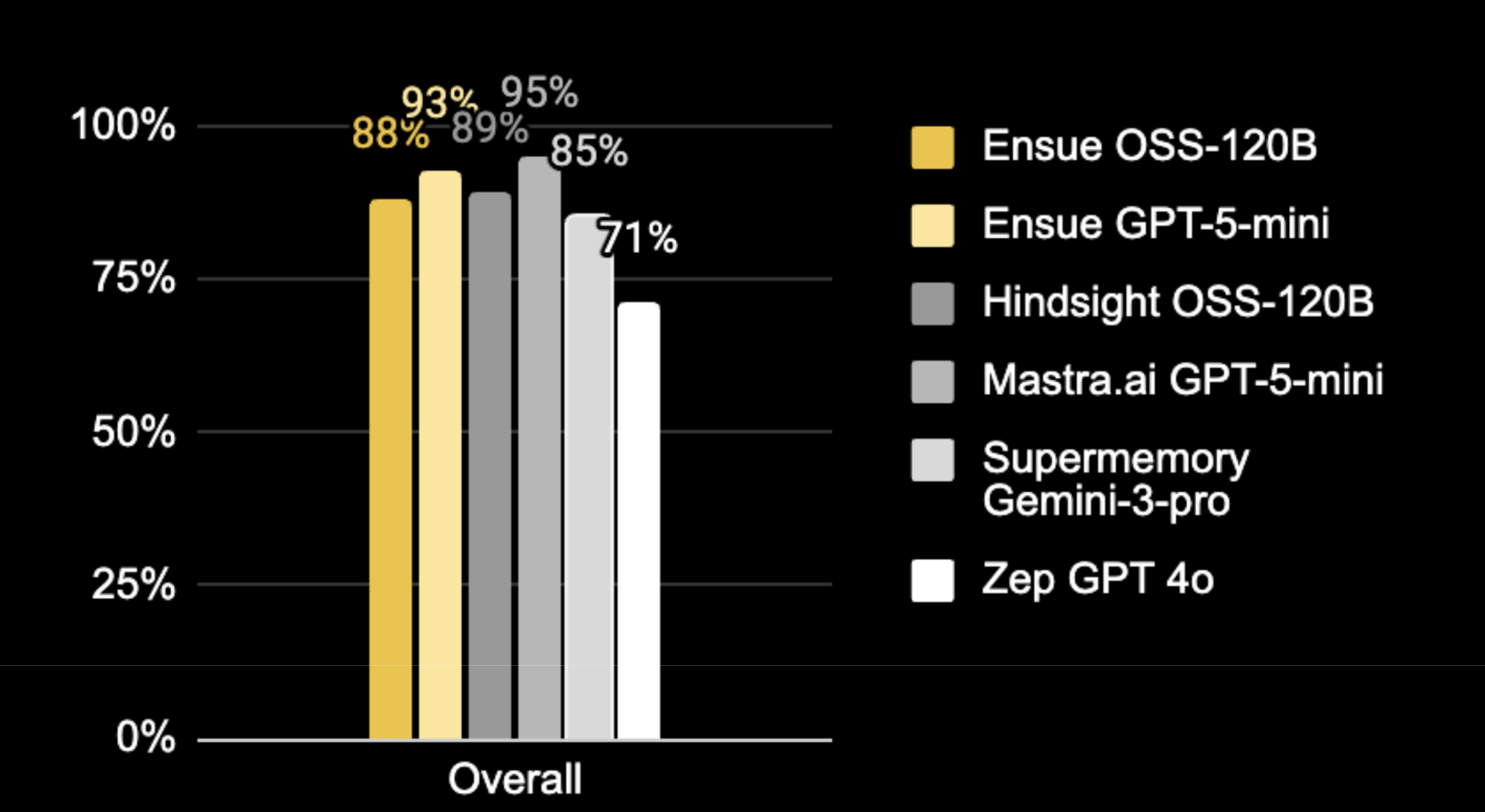
In single-session retrieval, our accuracy ranges from 96-100%. At this level, anything stored in a session can be found when needed. The amount an agent can reliably remember stops being bound by the context window size.
You can store far more than fits in any model's context window and still retrieve it reliably. The practical ceiling shifts from “what the model can hold” to “what you've stored in persistent memory”.
| Open-Source Models | Proprietary Models | ||||
|---|---|---|---|---|---|
| Ensue OSS-120B |
Hindsight OSS-120B1 |
Mastra.ai GPT-5-mini2 |
Ensue GPT-5-mini |
Supermemory Gemini-32 |
|
| Single-session Preference | 100% | 87% | 100% | 100% | 70% |
| Single-session User | 97% | 100% | 96% | 97% | 99% |
| Single-session Assistant | 96% | 98% | 95% | 100% | 98% |
| Knowledge Update | 86% | 92% | 96% | 96% | 90% |
| Temporal Reasoning | 86% | 86% | 96% | 91% | 82% |
| Multi-session | 81% | 81% | 87% | 87% | 77% |
| Single-Session Categories | 96-100% | 87-100% | 95-100% | 97-100% | 70-99% |
| Overall | 88% | 89% | 95% | 93% | 85% |
1 C. Latimer et al., Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects, arXiv:2512.12818, 2025. https://arxiv.org/abs/2512.12818
2 T. Barnes, Observational Memory: 95% on LongMemEval — A Human-Inspired Memory System for AI Agents, Mastra Research, 2026. https://mastra.ai/research/observational-memory
Model Agnostic Architecture: Higher Accuracy As Models Get Better
Our pipeline is designed to work with any model. When we swap in GPT-5-mini, the same model powering Mastra's top score, Ensue reaches 93%, within 2 points of the leading system. With open-source models alone, we still score 88%.
The gap between 88% and 93% is what the better model adds, and the 88% score is what our architecture delivers on its own with open-source models. As open-source models continue to improve, our accuracy ceiling will rise without changing the architecture.
What This Powers
Early users already use the Ensue memory network to persist their agents' memory across sessions - in OpenClaw, Claude Code, and other tools - and share context across models, agents, and environments. This retrieval system is coming to Ensue to power that search and bring even higher accuracy.
We demonstrated what accurate retrieval and agent orchestration enable with a Putnam-level math problem that no single agent could easily solve. Prover agents needed to find tactics and lemmas discovered by other agents by meaning, not by key name. Without accurate retrieval, shared memory is just a noisy database.
Who This Is For
If you're building agents that accumulate memory over time, retrieval quality will eventually become your bottleneck. We're working with teams to deploy this retrieval system in their environments, whether cloud-hosted, on-prem, or hybrid. A few scenarios where we can help:
- You need memory infrastructure that runs on your hardware. Regulated industries, sensitive data, or latency requirements that rule out API-based retrieval. Our pipeline runs entirely on open-source models.
- Your agents need to share context. Multiple agents or models that need to read from and write to the same memory, without retrieval quality collapsing as the shared pool grows.
- You're building an agent product and memory is degrading at scale. RAG pipelines that work at 100 memories often degrade at 10,000. We can help you evaluate and upgrade your retrieval architecture.
If any of these sound like you, book time with the founding team, or send us an email founder@ensue.dev
Get started
Ensue plugs into any agent stack. Add persistent, searchable, and portable memory to your agents in a few lines. Get started with Ensue.
We're a team from distributed systems, obsessed with agent coordination and memory. Join our Discord and Follow us on X to follow our work.